Publications
Paper publications in journals and congresses. * denotes equal contribution.
2025
- *SEM @ EMNLP 2025
 Semantic Prosody in Machine Translation: the English-Chinese Case of Passive StructuresXinyue Ma, Pol Pastells, Mariona Taulé Delor, and Mireia FarrúsIn Proceedings of the 14th Joint Conference on Lexical and Computational Semantics (*SEM 2025) , Nov 2025
Semantic Prosody in Machine Translation: the English-Chinese Case of Passive StructuresXinyue Ma, Pol Pastells, Mariona Taulé Delor, and Mireia FarrúsIn Proceedings of the 14th Joint Conference on Lexical and Computational Semantics (*SEM 2025) , Nov 2025Semantic prosody is a collocational meaning formed through the co-occurrence of a linguistic unit and a consistent series of collocates, which should be treated separately from semantic meaning. Since words that are literal translation of each other may have different semantic prosody, more attention should be paid to this linguistic property in order to generate accurate translation. However, current machine translation models cannot handle this problem. To bridge the gap, we propose an approach to teach machine translation models about semantic prosody of a specific structure. We focus on Chinese BEI passives and create a dataset of English-Chinese sentence pairs with the purpose of demonstrating the negative semantic prosody of BEI passives. Then we fine-tune OPUS-MT, NLLB-600M and mBART50-mmt models with our dataset for the English-Chinese translation task. Our results show that fine-tuned MT models perform better on using BEI passives for translating unfavourable content and avoid using it for neutral and favourable content. Also, in NLLB-600M, which is a multilingual model, this knowledge of semantic prosody can be transferred from English-Chinese translation to other language pairs, such as Spanish-Chinese.
@inproceedings{ma-etal-2025-semantic, title = {Semantic Prosody in Machine Translation: the {E}nglish-{C}hinese Case of Passive Structures}, author = {Ma, Xinyue and Pastells, Pol and Delor, Mariona Taul{\'e} and Farr{\'u}s, Mireia}, editor = {Frermann, Lea and Stevenson, Mark}, booktitle = {Proceedings of the 14th Joint Conference on Lexical and Computational Semantics (*SEM 2025)}, month = nov, year = {2025}, address = {Suzhou, China}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2025.starsem-1.5/}, doi = {10.18653/v1/2025.starsem-1.5}, pages = {59--69}, isbn = {979-8-89176-340-1}, } - CLEF 2025
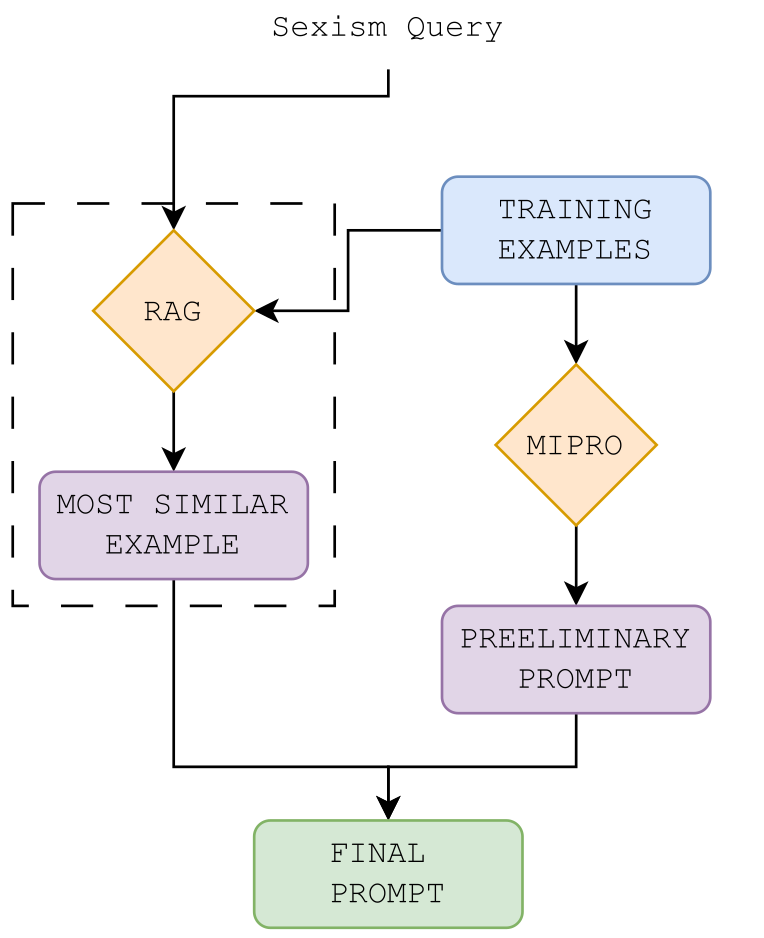 CLiC at EXIST 2025: Combining Fine-tuning and Prompting with Learning with Disagreement for Sexism DetectionPol Pastells*, Mauro Vázquez*, Mireia Farrús, and Mariona TauléCEUR Proceedings CLEF, Nov 2025
CLiC at EXIST 2025: Combining Fine-tuning and Prompting with Learning with Disagreement for Sexism DetectionPol Pastells*, Mauro Vázquez*, Mireia Farrús, and Mariona TauléCEUR Proceedings CLEF, Nov 2025We present the CLiC group’s participation in the EXIST 2025 shared task, focusing on sexism detection in social media content. Our work addresses three subtasks: sexism identification (Task 1.1), source intention detection (Task 1.2), and sexism categorization (Task 1.3). We employed BERT \citedevlin2019bert fine-tuning for Task 1.1 (binary sexism classification) and DSPy-based prompt optimization for Tasks 1.2 and 1.3, leveraging the initial classification outcomes. A key aspect of our approach is a Learning with Disagreement framework that utilizes annotator demographic information to model diverse perceptions of sexism. Our experimental design included three runs, exploring BERT-based methods for Task 1.1 and contrasting prompt-based methods, including variants with annotator information and Retrieval-Augmented Generation (RAG), for the subsequent tasks. Results demonstrate that BERT fine-tuning significantly surpassed prompt-based methods for Task 1.1, where our approach secured 9th place out of 67 participants in the soft label category. The integration of annotator information proved vital, leading to substantial performance gains across all tasks. The impact of RAG, however, remained inconclusive. These findings highlight the enduring effectiveness of fine-tuned models for core classification, while emphasizing the necessity of annotator-aware approaches for handling subjective concepts like sexism.
@article{pastells2024context, title = {CLiC at EXIST 2025: Combining Fine-tuning and Prompting with Learning with Disagreement for Sexism Detection}, author = {Pastells*, Pol and V{\'a}zquez*, Mauro and Farr{\'u}s, Mireia and Taul{\'e}, Mariona}, year = {2025}, journal = {CEUR Proceedings CLEF}, } - COLM 2025
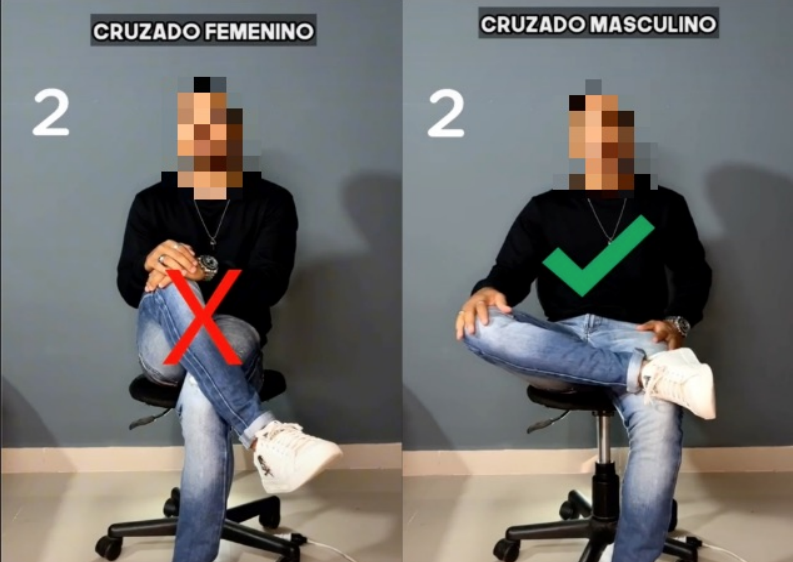 MuSeD: A Multimodal Spanish Dataset for Sexism Detection in Social Media VideosLaura De Grazia, Pol Pastells, Mauro Vázquez Chas, Desmond Elliott, Danae Sánchez Villegas, Mireia Farrús, and Mariona TauléarXiv preprint arXiv:2504.11169, Nov 2025
MuSeD: A Multimodal Spanish Dataset for Sexism Detection in Social Media VideosLaura De Grazia, Pol Pastells, Mauro Vázquez Chas, Desmond Elliott, Danae Sánchez Villegas, Mireia Farrús, and Mariona TauléarXiv preprint arXiv:2504.11169, Nov 2025Sexism is generally defined as prejudice and discrimination based on sex or gender, affecting every sector of society, from social institutions to relationships and individual behavior. Social media platforms amplify the impact of sexism by conveying discriminatory content not only through text but also across multiple modalities, highlighting the critical need for a multimodal approach to the analysis of sexism online. With the rise of social media platforms where users share short videos, sexism is increasingly spreading through video content. Automatically detecting sexism in videos is a challenging task, as it requires analyzing the combination of verbal, audio, and visual elements to identify sexist content. In this study, (1) we introduce MuSeD, a new Multimodal Spanish dataset for Sexism Detection consisting of 11 hours of videos extracted from TikTok and BitChute; (2) we propose an innovative annotation framework for analyzing the contribution of textual and multimodal labels in the classification of sexist and non-sexist content; and (3) we evaluate a range of large language models (LLMs) and multimodal LLMs on the task of sexism detection. We find that visual information plays a key role in labeling sexist content for both humans and models. Models effectively detect explicit sexism; however, they struggle with implicit cases, such as stereotypes, instances where annotators also show low agreement. This highlights the inherent difficulty of the task, as identifying implicit sexism depends on the social and cultural context.
@article{de2025mused, title = {MuSeD: A Multimodal Spanish Dataset for Sexism Detection in Social Media Videos}, author = {De Grazia, Laura and Pastells, Pol and Chas, Mauro V{\'a}zquez and Elliott, Desmond and Villegas, Danae S{\'a}nchez and Farr{\'u}s, Mireia and Taul{\'e}, Mariona}, journal = {arXiv preprint arXiv:2504.11169}, year = {2025}, } - Interspeech 2025
 SCRIBAL: A Digital Transcription Tool in Higher EducationJavier Román, Pol Pastells, Mauro Vázquez, Clara Puigventós, Montserrat Nofre, Mariona Taulé, and Mireia FarrúsIn Interspeech 2025 , Nov 2025
SCRIBAL: A Digital Transcription Tool in Higher EducationJavier Román, Pol Pastells, Mauro Vázquez, Clara Puigventós, Montserrat Nofre, Mariona Taulé, and Mireia FarrúsIn Interspeech 2025 , Nov 2025SCRIBAL is a digital transcription and translation tool for university teaching, covering Catalan transcription and translation to the main foreign languages in class. Based on Whisper, SCRIBAL is fine-tuned for specific Catalan dialectal varieties and specialized academic terminology. It becomes an essential tool for accessibility, as well as for breaking language barriers and preserving the national languages in higher education.
@inproceedings{roman25_interspeech, title = {SCRIBAL: A Digital Transcription Tool in Higher Education}, author = {Román, Javier and Pastells, Pol and Vázquez, Mauro and Puigventós, Clara and Nofre, Montserrat and Taulé, Mariona and Farrús, Mireia}, year = {2025}, booktitle = {Interspeech 2025}, pages = {4958--4959}, issn = {2958-1796}, }




2024
- SEPLN 2024
 Overview of DETESTS-Dis at IberLEF 2024: DETEction and classification of racial STereotypes in Spanish-Learning with DisagreementWolfgang S Schmeisser-Nieto, Pol Pastells, Simona Frenda, Alejandro Ariza-Casabona, Mireia Farrús, Paolo Rosso, and Mariona TauléProcesamiento del Lenguaje Natural, Nov 2024
Overview of DETESTS-Dis at IberLEF 2024: DETEction and classification of racial STereotypes in Spanish-Learning with DisagreementWolfgang S Schmeisser-Nieto, Pol Pastells, Simona Frenda, Alejandro Ariza-Casabona, Mireia Farrús, Paolo Rosso, and Mariona TauléProcesamiento del Lenguaje Natural, Nov 2024This paper presents an overview of the DETESTS-Dis shared task as part of the IberLEF 2024 Workshop on Iberian Languages Evaluation Forum, within the framework of the SEPLN 2024 conference. We proposed two hierarchical subtasks: In subtask 1, participants had to determine the presence of stereotypes in the texts. For subtask 2, participants had to decide which texts labeled with stereotypes were implicit stereotypes. The DETESTS-Dis dataset contains 12,111 comment sentences and tweets in response to newspaper articles and verified racial hoaxes involving immigration in Spanish. 15 teams signed up to participate, 6 of which sent runs, and 3 of them sent their working notes. In this paper, we provide information about the training and test datasets, the systems used by the participants, the evaluation metrics of the systems and their results.
@article{schmeisser2024overview, title = {Overview of DETESTS-Dis at IberLEF 2024: DETEction and classification of racial STereotypes in Spanish-Learning with Disagreement}, author = {Schmeisser-Nieto, Wolfgang S and Pastells, Pol and Frenda, Simona and Ariza-Casabona, Alejandro and Farr{\'u}s, Mireia and Rosso, Paolo and Taul{\'e}, Mariona}, journal = {Procesamiento del Lenguaje Natural}, volume = {73}, pages = {323--333}, year = {2024}, } - SEPLN 2024
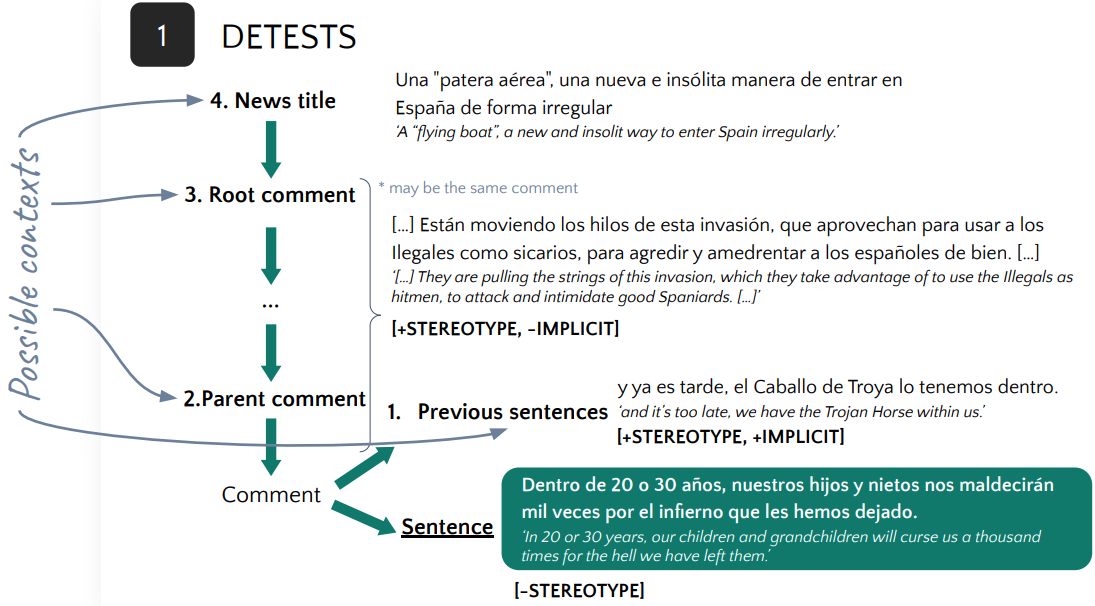 Context-Aware Stereotype Detection: Conversational Thread Analysis on BERT-based ModelsPol Pastells, Wolfgang S Schmeisser-Nieto, Simona Frenda, and Mariona TauléCEUR Proceedings SEPLN, Nov 2024
Context-Aware Stereotype Detection: Conversational Thread Analysis on BERT-based ModelsPol Pastells, Wolfgang S Schmeisser-Nieto, Simona Frenda, and Mariona TauléCEUR Proceedings SEPLN, Nov 2024Conversational context plays a pivotal role in disambiguating messages in human communication. In this study, we investigate the impact of contextual information on detecting stereotypes related to immigrants using various BERT-based models. We use two Spanish corpora containing news comments and tweets, together with their conversational threads, annotated with stereotypes related to immigrants in Spain. The results show that the influence of context on stereotype detection varies across different models, corpora and context levels. Although context can enhance performance in specific scenarios, it does not consistently improve stereotype detection across all the levels of contexts. Our comprehensive evaluation underscores the complex relationship between context and stereotype identification when we use BERT-based Language Models. In particular, we found that the number of texts benefiting from contextual analysis may be too limited for the models to effectively learn from.
@article{pastells2024contexu, title = {Context-Aware Stereotype Detection: Conversational Thread Analysis on BERT-based Models}, author = {Pastells, Pol and Schmeisser-Nieto, Wolfgang S and Frenda, Simona and Taul{\'e}, Mariona}, year = {2024}, journal = {CEUR Proceedings SEPLN}, } - LREC-COLING 2024
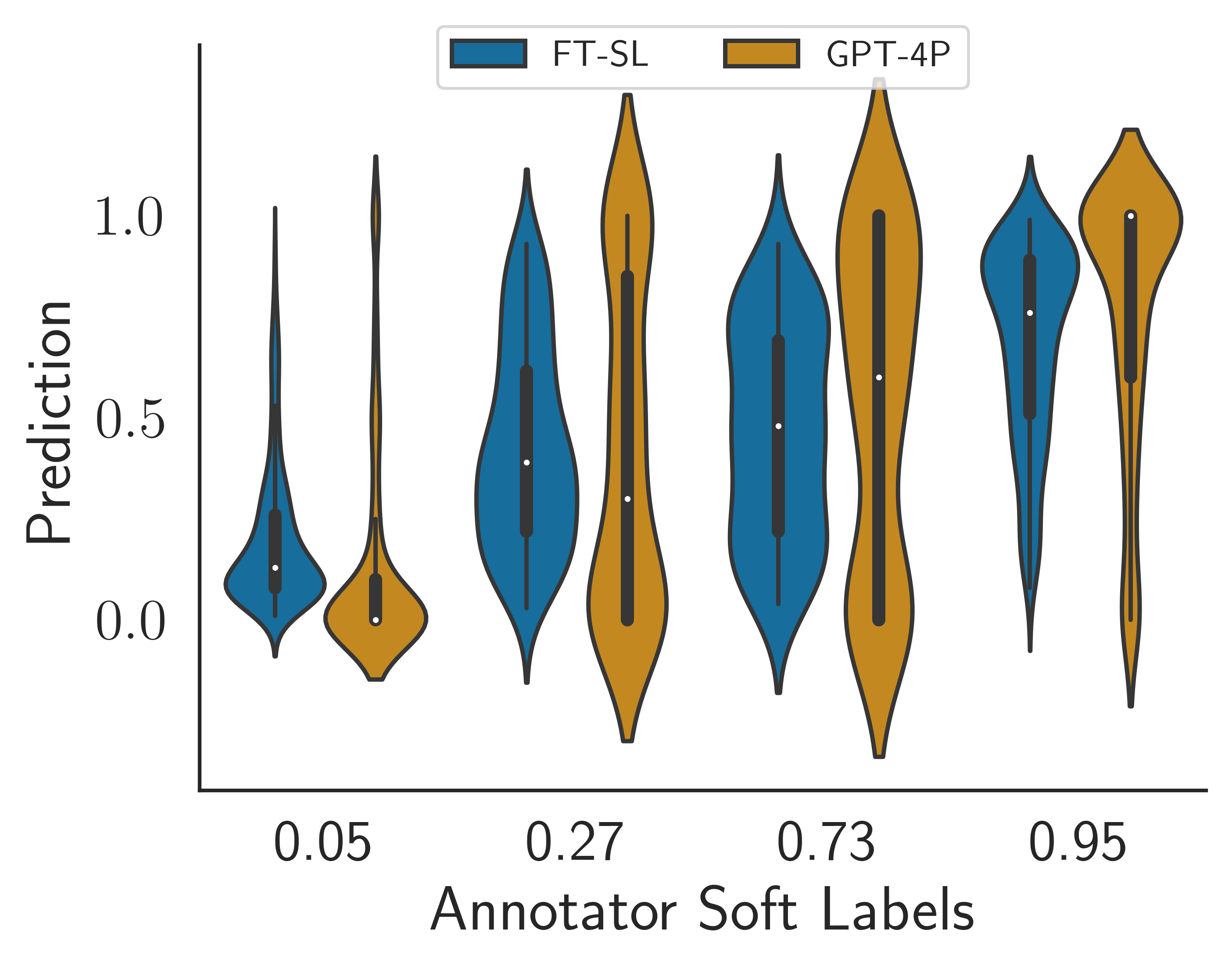 Human vs. Machine Perceptions on Immigration StereotypesWolfgang S. Schmeisser-Nieto*, Pol Pastells*, Simona Frenda, and Mariona TauleIn Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , May 2024
Human vs. Machine Perceptions on Immigration StereotypesWolfgang S. Schmeisser-Nieto*, Pol Pastells*, Simona Frenda, and Mariona TauleIn Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , May 2024The increasing popularity of natural language processing has led to a race to improve machine learning models that often leaves aside the core study object, the language itself. In this study, we present classification models designed to detect stereotypes related to immigrants, along with both quantitative and qualitative analyses, shedding light on linguistic distinctions in how humans and various models perceive stereotypes. Given the subjective nature of this task, one of the models incorporates the judgments of all annotators by utilizing soft labels. Through a comparative analysis of BERT-based models using both hard and soft labels, along with predictions from GPT-4, we gain a clearer understanding of the linguistic challenges posed by texts containing stereotypes. Our dataset comprises Spanish Twitter posts collected as responses to immigrant-related hoaxes, annotated with binary values indicating the presence of stereotypes, implicitness, and the requirement for conversational context to understand the stereotype. Our findings suggest that both model prediction confidence and inter-annotator agreement are higher for explicit stereotypes, while stereotypes conveyed through irony and other figures of speech prove more challenging to detect than other implicit stereotypes.
@inproceedings{schmeisser-nieto-etal-2024-human-vs, title = {Human vs. Machine Perceptions on Immigration Stereotypes}, author = {Schmeisser-Nieto*, Wolfgang S. and Pastells*, Pol and Frenda, Simona and Taule, Mariona}, year = {2024}, month = may, booktitle = { Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) }, publisher = {ELRA and ICCL}, address = {Torino, Italia}, pages = {8453--8463}, url = {https://aclanthology.org/2024.lrec-main.741}, editor = {Calzolari, Nicoletta and Kan, Min-Yen and Hoste, Veronique and Lenci, Alessandro and Sakti, Sakriani and Xue, Nianwen}, } - Nuclear Fusion
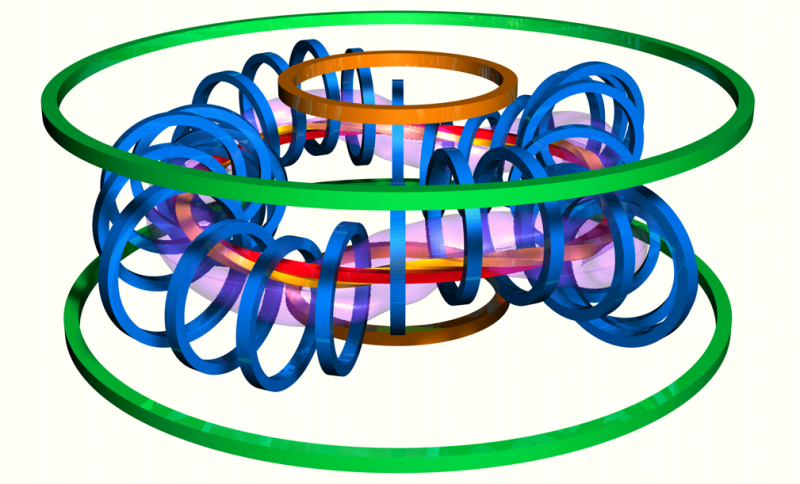 Modeling of frequency-sweeping Alfvén modes in the TJ-II stellaratorAG Ghiozzi, MJ Mantsinen, Pol Pastells, DA Spong, AV Melnikov, LG Eliseev, and SE SharapovNuclear Fusion, May 2024
Modeling of frequency-sweeping Alfvén modes in the TJ-II stellaratorAG Ghiozzi, MJ Mantsinen, Pol Pastells, DA Spong, AV Melnikov, LG Eliseev, and SE SharapovNuclear Fusion, May 2024Alfvénic activity has been observed in the TJ-II stellarator which resembles the frequency sweeping demonstrated by Alfvén cascade modes in tokamaks. A numerical validation study was conducted using a reduced magnetohydrodynamic (MHD) model to show that such modes could only have been observed in discharges where the rotational transform profile was non-monotonic. During experiments, coil current was varied which resulted in shifting of the minimum value of the rotational transform profile. To mimic this effect, we study the Alfvénic activity predicted by the reduced MHD model for a set of input rotational transform profiles with varying minima. A mode is found whose toroidal and poloidal mode numbers match those predicted in experiments which sweeps downward/upward in frequency as the minimum value of the rotational transform profile is increased/decreased. The results serve as a demonstration of the validity and utility of MHD spectroscopy.
@article{ghiozzi2024modeling, title = {Modeling of frequency-sweeping Alfv{\'e}n modes in the TJ-II stellarator}, author = {Ghiozzi, AG and Mantsinen, MJ and Pastells, Pol and Spong, DA and Melnikov, AV and Eliseev, LG and Sharapov, SE}, year = {2024}, journal = {Nuclear Fusion}, publisher = {IOP Publishing}, volume = {64}, number = {3}, pages = {036005}, } - Scientific Reports
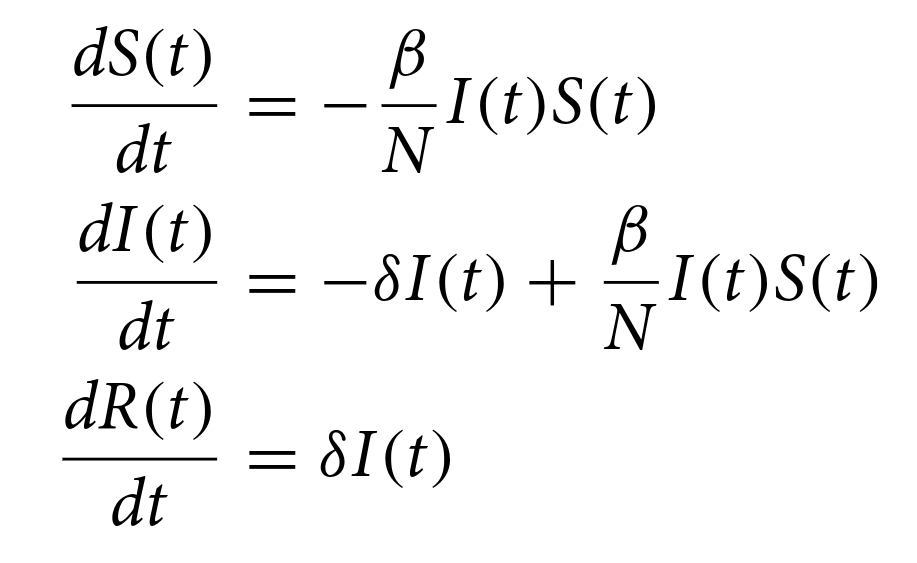 ePyDGGA: automatic configuration for fitting epidemic curvesJosep Alòs*, Carlos Ansótegui*, Ivan Dotu*, Manuel Garcı́a-Herranz*, Pol Pastells*, and Eduard Torres*Scientific Reports, May 2024
ePyDGGA: automatic configuration for fitting epidemic curvesJosep Alòs*, Carlos Ansótegui*, Ivan Dotu*, Manuel Garcı́a-Herranz*, Pol Pastells*, and Eduard Torres*Scientific Reports, May 2024Many epidemiological models and algorithms are used to fit the parameters of a given epidemic curve. On many occasions, fitting algorithms are interleaved with the actual epidemic models, which yields combinations of model-parameters that are hard to compare among themselves. Here, we provide a model-agnostic framework for epidemic parameter fitting that can (fairly) compare different epidemic models without jeopardizing the quality of the fitted parameters. Briefly, we have developed a Python framework that expects a Python function (epidemic model) and epidemic data and performs parameter fitting using automatic configuration. Our framework is capable of fitting parameters for any type of epidemic model, as long as it is provided as a Python function (or even in a different programming language). Moreover, we provide the code for different types of models, as well as the implementation of 4 concrete models with data to fit them. Documentation, code and examples can be found at https://ulog.udl.cat/static/doc/epidemic-gga/html/index.html.
@article{alos2024epydgga, title = {ePyDGGA: automatic configuration for fitting epidemic curves}, author = {Al{\`o}s*, Josep and Ans{\'o}tegui*, Carlos and Dotu*, Ivan and Garc{\'\i}a-Herranz*, Manuel and Pastells*, Pol and Torres*, Eduard}, year = {2024}, journal = {Scientific Reports}, publisher = {Nature Publishing Group UK London}, volume = {14}, number = {1}, pages = {784}, }





2022
- EPS Plasma PhysicsModeling of Alfven cascades in the TJ-II stellarator with STELLGAP and AE3D codesAG Ghiozzi, M Mantsinen, Pol Pastells, DA Spong, AV Melnikov, and SE SharapovIn 48th EPS Conference on Plasma Physics, June , May 2022
@inproceedings{ghiozzi2022modeling, title = {Modeling of Alfven cascades in the TJ-II stellarator with STELLGAP and AE3D codes}, author = {Ghiozzi, AG and Mantsinen, M and Pastells, Pol and Spong, DA and Melnikov, AV and Sharapov, SE}, booktitle = {48th EPS Conference on Plasma Physics, June}, volume = {27}, year = {2022}, }